AI 内容理解平台关键模块实施方案
大文件上传截断方案
方案:
- 文档按大小限制上传(150M),按字符数限制解析存储(20w);
- 视频按大小限制上传(1G),按字幕字符数限制解析存储(5w);
- 按字符数,限制模型总结字符长度,见 1.1 各模型输入长度限制。
优点:
- 响应速度更快,前端用户交互体验更好;
- 节省调用大模型成本,见 1.3 大模型费用。
缺点:
- 文件总结的内容不完整
各模型输入长度与耗时
各个模型单次的token输入长度限制有差异,并且请求频率也有限制,通过测试对比,以下是测试结果:

最终方案如下:

同类产品限制
通过调研发现,目前同类产品都存在以下限制:

模型费用
| 模型名称 | 输入 | 输出 | 链接 |
|---|---|---|---|
| 智谱:GLM-4 | 0.1元/千tokens | 同输入 | ZHIPU AI OPEN PLATFORM |
| 百川:Baichuan2 | 0.008元/千tokens | 同输入 | 百川大模型-汇聚世界知识 创作妙笔生花-百川智能 |
| Kimi:moonshot-v1-32k | 0.012元/千tokens | 同输入 | apidoc-team.smzdm.com |
| 千问:qwen-72b-chat | 0.02元/千tokens | 同输入 | help.aliyun.com |
| 文心:ernie-speed-128k | 0.004元/千tokens | 0.008元/千tokens | cloud.baidu.com |
| gpt-4 | US$30.00 / 1M tokens | US$60.00 / 1M tokens | https://openai.com/api/pricing |
| gpt-35-turbo | US$0.50 / 1M tokens | US$1.50 / 1M tokens | https://openai.com/api/pricing |
多模型切换场景:上下文管理方案
会话的第一个问题为默认问题,只要切换模型就会自动发起问答。
方案一
切换模型时,读取上一模型的问答列表存储在堆栈中;
与当前模型的问答列表对比,没有问过的留下,按顺序提示用户;
用户用户连续跳过3个问题,则清空堆栈。
优点:
- 轻量。
缺点:
刷新页面后丢失提示数据;
清空堆栈后所有模型都会丢失数据。
方案二
维护一个问题堆栈和一个map,key为问题的hash,value为列表;
当开始问下一个问题时就压入堆栈,并存储该模型名称到value列表中;
切换模型时,在第一个问题回答完后,从堆栈中取问题,按顺序提示用户是否问第二、三…个问题;
如果用户问了,则记录该模型名称到value列表中,如果跳过了,也记录该模型名称到value列表中;
如果用户连续跳过了3个,则把堆栈中所有该模型没问的问题都记录一下,放在对应的value列表中;
如果用户新增问题,则继续压入堆栈中,重复2、3、4、5;
问题对应的value值存满后,可删除;
持久化该堆栈和map,应对刷新场景。
优点:
- 可保留所有数据。
缺点:
- 相比方案一较重,看看是否有必要。
数据结构
1 | [ |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Hllinc!
相关推荐
2025-01-11
AnalyzeSphere V1.1 新版上线
续更中。。。 产品转型 添加 SEO 功能 增加更多统计分析模块
2024-11-05
探索数据的无限可能:欢迎来到 AnalyzeSphere!
今天和大家分享一个新产品,它可能会改变你对数据分析的看法。 什么是 AnalyzeSphere?简单来说,AnalyzeSphere 是一个超级强大的数据分析工具,旨在帮助你更轻松地理解和利用数据。无论你是企业主、市场营销人员,还是只对数据感兴趣的朋友,我们都希望这个工具能为你带来帮助。 为什么选择我们? 简单易用:我们知道,很多数据工具都复杂得让人头疼。AnalyzeSphere 采用直观的界面设计,让你可以快速上手,不用再花时间去学习繁琐的操作。 智能分析:我们的智能算法会自动帮你找出数据中的趋势和模式,让你能够快速做出决策。这就像有一个聪明的小助手在旁边为你工作! 实时更新:在这个瞬息万变的世界里,我们确保你的数据始终保持最新,让你随时随地都能掌握一手信息。 适合谁?无论你是想要深入了解市场动态的创业者,还是希望优化业务流程的团队成员,AnalyzeSphere 都能为你提供所需的洞察力。我们相信,数据应该是每个人都能轻松获取和理解的资源。 试试看吧!如果你对这个工具感兴趣,不妨访问...
2026-01-04
Agent Skill:让 AI 智能体拥有真正执行力的核心能力
在 AI Agent 的世界里,大语言模型是大脑,而 Skill 是双手。没有 Skill 的 Agent 只能”纸上谈兵”,而拥有丰富 Skill 的 Agent 才能真正改变世界。今天,我们来深入探讨 Agent Skill——智能体的核心执行能力。 什么是 Agent Skill?Agent Skill(智能体技能)是指 AI Agent 能够执行的特定能力或功能。它是连接 LLM(大语言模型)与现实世界的桥梁,让智能体从”会说”变成”会做”。 简单来说: Skill = 让 Agent 真正能够完成任务的能力单元 一个 Skill 通常包含三个核心要素: 输入(Input):技能执行所需的参数 逻辑(Logic):技能的具体实现 输出(Output):技能执行后的返回结果 Skill 的核心结构:Reference 与 Script一个完整的 Agent Skill 不仅仅是一个函数定义,它还包含两个关键组成部分:Reference 和 Script。这两者共同构成了技能的第三层结构,使 Agent 能够处理更复杂的任务。 📚...
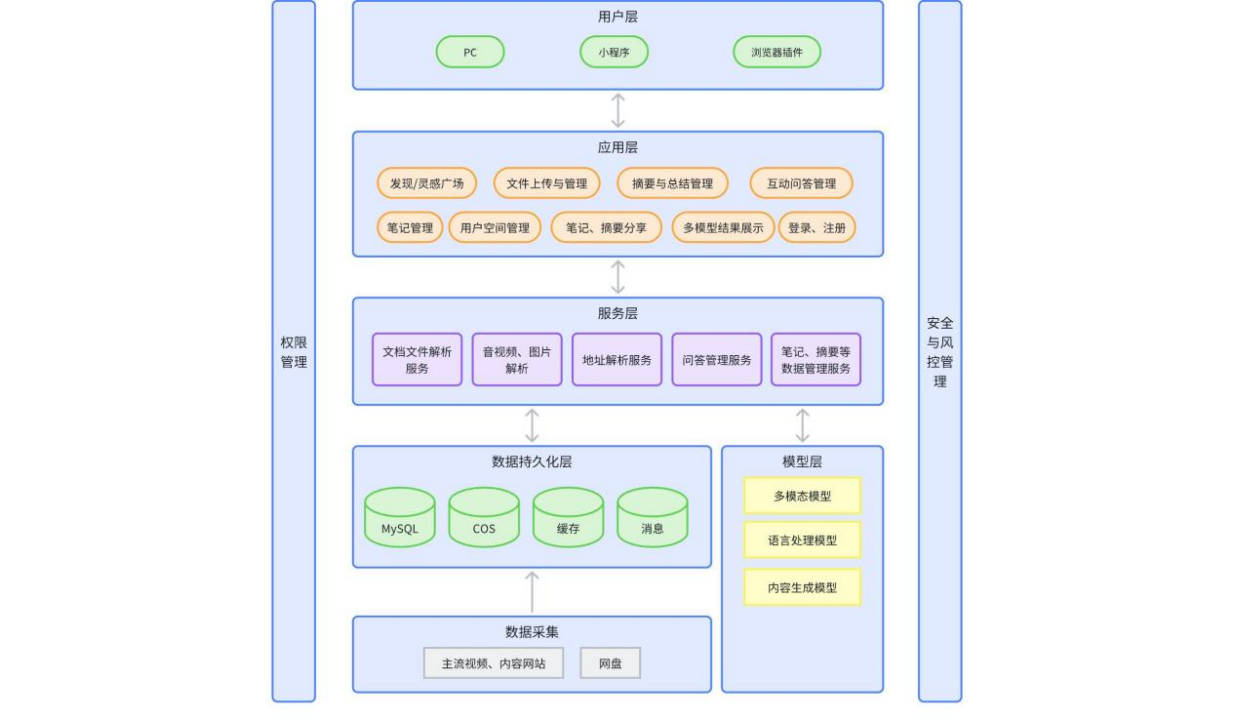
2024-12-13
AI 内容理解平台技术方案
系统架构图功能模块 多模态模型: 实现音频、视频、图片的解析功能; 语言处理模型:关键词提取等。 内容生成模型:生成摘要和总结。 技术架构图 业务数据流程图 代码工程结构图Web 服务工程结构 关键技术点全文总结文章内容长度超过模型处理上限工程层:工程层面会按业务场景约束文件的大小,然后一次发送全部内容给到模型。 模型层:将文章分为多段进行处理,再将每次的结果合并成一个新的文章,再次进行处理,最终返回摘要总结。 功能模块设计 数据采集服务主流视频、内容网站计划每天各主流网站按 Top 10 抓取,预计每天数据量在200条左右。 小红书、知乎、公众号 B站、快手、抖音(pc端) 新浪、搜狐、网易、腾讯新闻 tt、youtobe 科技文献(主要AI圈),待确定 文件上传 word/pdf/txt/ppt等文本内容 仅文本层面处理 文本、图片都识别 网盘 百度网盘地址...
2025-08-26
Cotex — 竞对&市场&用户&内容的最佳洞察,用一句话开启
在这个信息爆炸的时代,竞对动态、市场趋势、用户反馈、内容热点——每一个维度都值得深入洞察。但传统的分析方式往往需要复杂的工具搭建、繁琐的数据处理,让很多人望而却步。 今天,我们来聊聊 **Cotex**——一款让洞察变得简单的 AI 工具。 什么是 Cotex?Cotex 是由杭州见微智助技术有限公司打造的智能洞察产品。正如其名,”见微知著,方能致远”——Cotex 致力于为你的事业提供有价值的洞见。 它的核心理念是: 不需要搭建复杂工作流、没有学习门槛——用一句话开启洞察之旅。 我们提供价值,而不是工具市面上有太多”工具”,却很少有产品真正关注价值输出。Cotex 的设计哲学与众不同: ✅ 我们提供 精准的竞对情报:实时追踪竞争对手的动态 深度的市场洞察:把握行业脉搏与发展趋势 真实的用户声音:聆听目标用户的需求与反馈 热门的内容分析:发现内容创作的灵感与机会 ❌ 我们不提供 差强人意的效果 不稳定的输出 对你没价值的结果 这就是 Cotex 的承诺——每一次洞察,都要为你创造真实价值。 为什么选择 Cotex?🎯...
2025-12-31
Google ADK:构建下一代 AI 智能体的开源利器
随着 AI 技术的飞速发展,智能体(Agent)已成为连接大模型与现实世界的关键桥梁。今天,我们来聊聊 Google 推出的 Agent Development Kit(ADK)——一款专为开发者打造的开源智能体开发框架。 什么是 Google ADK?Google ADK(Agent Development Kit)是谷歌于 2024 年推出的开源智能体开发框架。它采用代码优先的设计理念,提供了一套完整的工具和资源,支持从原型设计到生产部署的全流程开发。 虽然 ADK 针对 Gemini 和 Google 生态系统进行了优化,但它是模型无关、部署无关的,并且与其他框架(如 LangChain、CrewAI)兼容,让开发者能够灵活选择技术栈。 核心架构ADK 的架构由五个关键组件构成: 1. 模型(Models)模型是智能体的”大脑”,负责理解和生成自然语言。ADK 支持接入多种大语言模型,开发者可以根据需求选择最适合的模型。 2. 工具(Tools)工具为智能体提供执行特定任务的能力,例如: 数据库查询 API 调用 代码执行 网络搜索 文件操作 ADK...
评论