提升商品检索结果相关性
命中前提:
- 库里存在该商品或与该商品有关联
- 关键词尽可能属于商品 title 的子串,或和商品 title 相关
- 关键词不能只有型号,要有品牌等信息
- 价格区间需要正确传入
检索服务流程
前端通过交互界面,输入一段 query,发送请求到检索服务,检索服务根据该 query 去库里查,分别查 ES 库和 Milvus 库,查出来之后通过 RRF 做个排序,然后把结果返回给前端。
这样做的话,结果的准确性完全取决于用户的关键词是什么。
这里涉及到几个关键环节:
用户输入 query 环节
服务接收并处理 query 环节
根据 query 查询数据库环节
从库中查询到数据返回给用户环节

优化方案
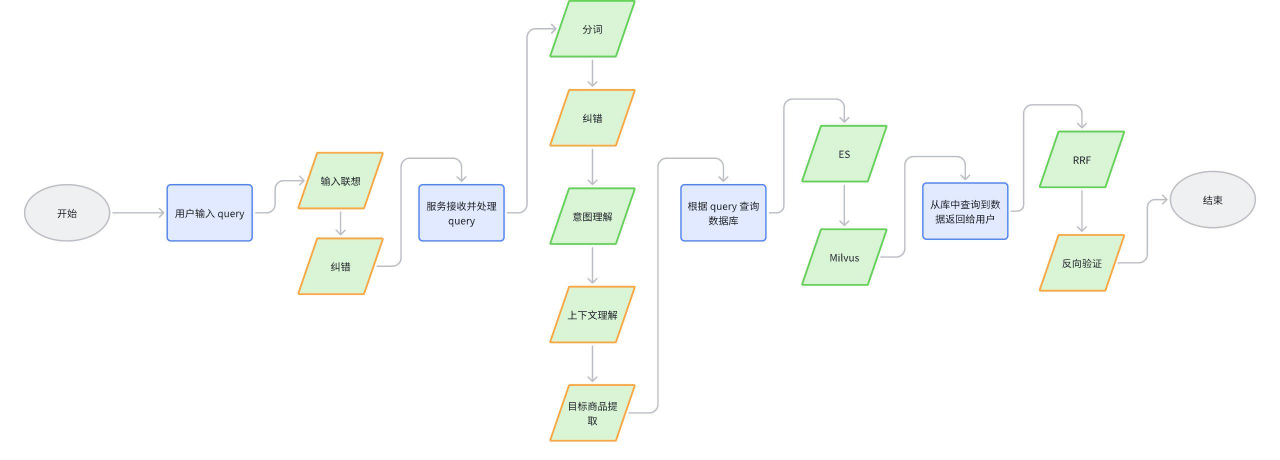
用户输入 query 环节
在用户输入环节进行优化,提供输入联想、纠错等功能。
针对微信公众号这种前端输入无法控制的场景,可能无法在输入这块直接提供优化,但是也可以后置,比如发送完了之后再问一下用户是否要修改为以下提供的 query 等。
输入联想
首先需要提供一个 query 模板库,该模板即为用户常输入的一些句式,然后通过用户输入的商品填充用户的输入。在输入到商品时,需要实时从库里查出对应的商品建议提示给用户。
这块需要准备句式模板库、库里的商品列表。
纠错
根据模板和库里的商品,进行实时纠错。纠错时需要提示用户确认。
服务接收并处理 query 环节
服务接收到 query 后,对该 query 做一个预处理,该预处理可以将用户的 query 进行分词、纠错、意图理解、上下文理解、商品提取等操作。
分词
分词的目的是为了更好的命中库中的数据,需要根据业务场景、库里已有的数据进行针对性分词。
需要实现的模块:
业务关键词库
商品关键词库
纠错
根据模板和库里的商品,进行纠错。纠错时需要提示用户确认。如果没有前一环节的纠错时启用该环节。
需要实现的模块:
模板库
纠错服务
意图理解
模型能力实现。
理解用户具体想要什么商品。
模型自身的理解能力
结合业务、商品库以及商品检索服务生成可提取准确关键词的意图理解
上下文理解
模型能力实现。
结合上下文理解用户具体想要什么商品。
目标商品提取
目标商品提取,使用库里的商品列表进行比对。这里需要考虑到商品的简称、别称等,可能也需要维护一个库。
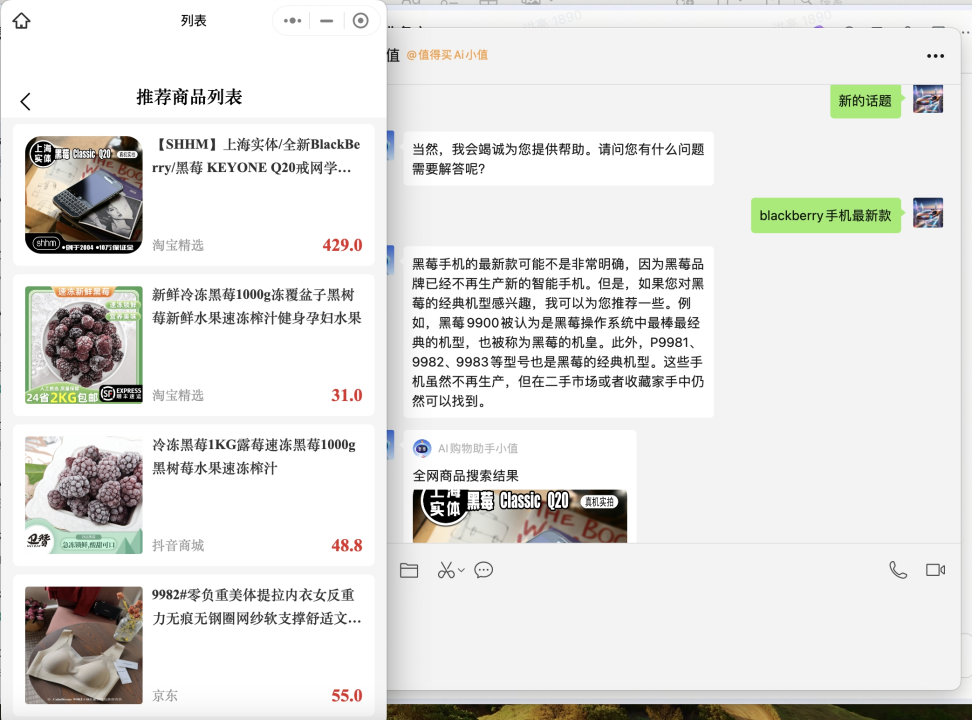
目前提取出来的关键词存在不明确的场景,比如输入blackberry手机,提取出来的关键词有:黑莓9900,P9981,9982,9983,第一个带有黑莓,其他的都只有型号,型号单独当关键词去商品库里查询时,结果和目标商品会差很多。
故,这里需要使用品牌加型号的方式当关键词。
 |
 |
提取逻辑
根据用户输入的 query,通过百科、评价总结等 tool 返回结果,再将几轮对话的上下文作为参数去调用百川模型,最终提取出来关键词。
句式模板库
商品列表
根据 query 查询数据库环节
这个环节主要依赖数据库自身能力,能优化的就是数据源和查询参数。
根据 query 查询数据库环节中,通过优化 ES 的匹配查询能力,以及 Milvus 的向量查询能力。
ES
ES 的匹配查询能力和分词器有关系,可以优化分词器配置或自定义分词器。
Milvus
Milvus 的向量查询能力,依赖对源数据的向量化及查询参数。
目前是使用商品的 title 字段进行的向量化,查询参数 nprobe 为 128。
从库中查询到数据返回给用户环节
RRF 排序
从库里查询到结果之后,目前是做了 RRF 的排序,即 ES 和 Milvus 都命中的排在前面。
目前 RRF 的 K 值是 60。
反向验证
将查询到的结果和目标商品再进行一次反向匹配,校验库的查询能力,命中的排在前面。